

Đó là nghiên cứu mới nhất của các nhà khoa học tại trường đại học California Santa Cruz, UC Davis, LuxiTech và đại học Soochow. Theo các nhà nghiên cứu, họ khẳng định đã tạo ra được cách vận hành mô hình ngôn ngữ lớn trên data center mới, qua đó cho phép thay đổi hoàn toàn cách vận hành mô hình ngôn ngữ AI. Một trong những quy trình tưởng chừng là vô cùng quan trọng khi vận hành LLM, đó là tính nhân ma trận trên những chip GPU chuyên biệt xử lý AI, theo các nhà khoa học Mỹ, hóa ra hoàn toàn có thể bị loại bỏ.
Nhân ma trận, matrix multiplication, viết tắt là MatMul hiện giờ là trung tâm của hầu hết mọi tác vụ tính toán neural network và machine learning hiện nay. GPU, với hàng nghìn, thậm chí hàng chục nghìn nhân xử lý, nên chúng có khả năng làm rất tốt và rất nhanh tác vụ này, vì chúng có thể tính toán song song hàng tỷ phép tính nhân phức tạp mỗi giây.
Suy cho cùng, chính khả năng tạo ra những chip xử lý hàng chục nghìn nhân tính toán, làm tính nhân ma trận rất nhanh chính là lý do khiến Nvidia từng trở thành tập đoàn với giá trị vốn hóa cao nhất hành tinh vào tuần trước, với giá trị đạt trên 3 nghìn tỷ USD. Hiện tại, Nvidia đang nắm giữ 98% tổng thị phần GPU phục vụ data center, với những khách hàng lớn, từ Microsoft, Google cho tới cả OpenAI.

Còn trong nghiên cứu khoa học mới, có tiêu đề "Thiết kế mô hình ngôn ngữ quy mô lớn không có nhân ma trận," các nhà nghiên cứu thuộc các trường đại học Mỹ đã mô tả việc tạo ra một mô hình với 2.7 tỷ tham số, vận hành không cần nhân ma trận, nhưng có khả năng tạo sinh ngôn ngữ ngang ngửa với những LLM thông thường đang được vận hành thương mại của nhiều tập đoàn và startup.
Nhân ma trận, matrix multiplication, viết tắt là MatMul hiện giờ là trung tâm của hầu hết mọi tác vụ tính toán neural network và machine learning hiện nay. GPU, với hàng nghìn, thậm chí hàng chục nghìn nhân xử lý, nên chúng có khả năng làm rất tốt và rất nhanh tác vụ này, vì chúng có thể tính toán song song hàng tỷ phép tính nhân phức tạp mỗi giây.
Suy cho cùng, chính khả năng tạo ra những chip xử lý hàng chục nghìn nhân tính toán, làm tính nhân ma trận rất nhanh chính là lý do khiến Nvidia từng trở thành tập đoàn với giá trị vốn hóa cao nhất hành tinh vào tuần trước, với giá trị đạt trên 3 nghìn tỷ USD. Hiện tại, Nvidia đang nắm giữ 98% tổng thị phần GPU phục vụ data center, với những khách hàng lớn, từ Microsoft, Google cho tới cả OpenAI.

Còn trong nghiên cứu khoa học mới, có tiêu đề "Thiết kế mô hình ngôn ngữ quy mô lớn không có nhân ma trận," các nhà nghiên cứu thuộc các trường đại học Mỹ đã mô tả việc tạo ra một mô hình với 2.7 tỷ tham số, vận hành không cần nhân ma trận, nhưng có khả năng tạo sinh ngôn ngữ ngang ngửa với những LLM thông thường đang được vận hành thương mại của nhiều tập đoàn và startup.
Họ cũng trình diễn thêm một mô hình 1.3 tỷ tham số, vận hành ở tốc độ 23.8 token nội dung mỗi giây, được tăng tốc bằng một con chip FPGA được phát triển riêng, chỉ dùng có 13W điện, bên cạnh điện năng mà GPU xử lý LLM tiêu thụ. Trình diễn này của các nhà khoa học cho thấy, "những chip FPGA chuyên biệt có thể mở đường cho việc phát triển những kiến trúc mô hình AI hiệu quả hơn và thân thiện hơn với phần cứng máy tính."
Kỹ thuật này cũng như báo cáo nghiên cứu vẫn chưa được thẩm định, nhưng nhóm các nhà nghiên cứu cho biết, công trình nghiên cứu của họ thách thức cách nghĩ phổ biến hiện nay, rằng phép nhân ma trận là thứ không thể thiếu trong quá trình xây dựng những mô hình ngôn ngữ hiệu suát cao. Họ lập luận rằng, cách tiếp cận của họ có thể giúp những LLM dễ tiếp cận hơn, hiệu quả hơn và bền vững hơn, đặc biệt là trong quá trình triển khai mô hình ngôn ngữ trên những thiết bị có giới hạn phần cứng, smartphone và laptop chẳng hạn.

Trong báo cáo nghiên cứu, các nhà khoa học đề cập đến BitNet, là kỹ thuật transformer 1-bit trước đó từng được đề cập trong một nghiên cứu khoa học hồi tháng 10/2023. Theo đó, BitNet thể hiện khả năng sử dụng những trọng số nhị phân và tam phân trong mô hình ngôn ngữ, từ đó đẩy mô hình ngôn ngữ lên ngưỡng 3 tỷ tham số nhưng hiệu năng xử lý vẫn ấn tượng.
Tuy nhiên BitNet vẫn phải phụ thuộc vào khả năng nhân ma trận trong cơ chế vận hành. Những giới hạn của BitNet chính là tiền đề và động lực để triển khai nghiên cứu hiện tại. Từ đó, các nhà khoa học phát triển được kỹ thuật vận hành neural network mà không cần nhân ma trận, kiến trúc được họ gọi là "MatMul-free", kể cả ở cơ chế attention trong quá trình neural network mô phỏng cách con người chú ý những từ khóa quan trọng trong một câu.
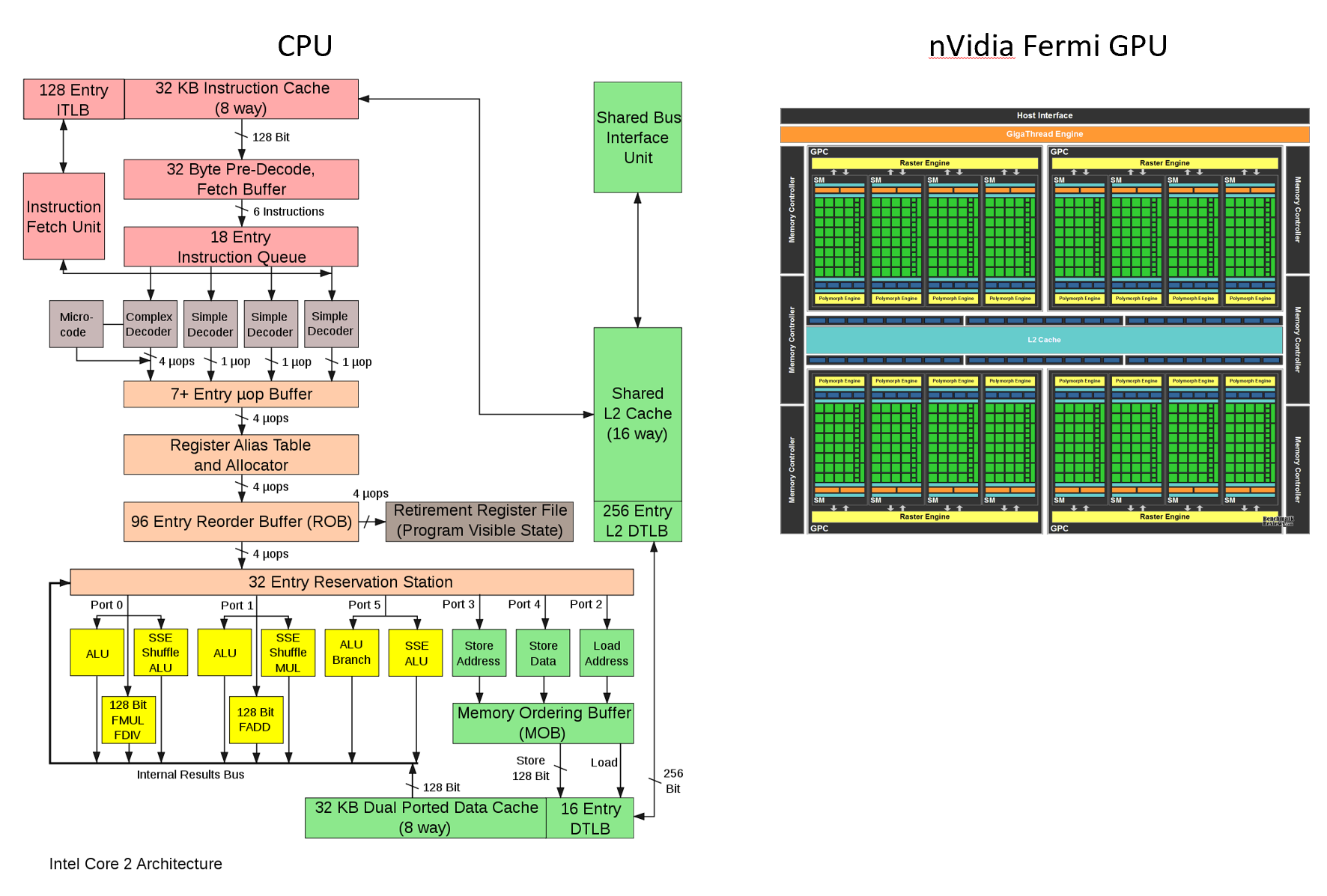
Để làm được điều này, các nhà khoa học đã tạo ra hai đột phá.
Thứ nhất, họ phát triển một mô hình ngôn ngữ mới, giới hạn nó chỉ được dùng những giá trị tam phân (-1. 0 và 1) thay vì những số thực dấu phẩy động như truyền thống. Về cơ bản giới hạn này sẽ khiến việc xử lý trở nên đơn giản hơn.
Quảng cáo
Thứ hai, các nhà nghiên cứu đã thiết kế lại hoàn toàn cơ chế mô phỏng tự chú ý (self-attention mechanism) trong một mô hình ngôn ngữ truyền thống, vốn là thứ cực kỳ tốn kém tài nguyên điện toán. Họ thay cơ chế này bằng một giải pháp thay thế đơn giản hơn, gọi là MLGRU, viết tắt của MatMul-free Linear Gated Recurrent Unit. Với cơ chế chú ý từ khóa của LLM này, mô hình ngôn ngữ sẽ xử lý những cụm từ lần lược, dựa vào những phép tính cơ bản thay vì phải nhân ma trận.
Rồi kế đến, họ ứng dụng Gated Linear Unit, GLU, một cơ chế vận hành kiểm soát dòng thông tin trong neural network, chỉ dùng trọng số tam phân trong quá trình channel mixing. Quá trình này kết hợp và biến đổi những khía cạnh hoặc chi tiết của dữ liệu mà AI đang xử lý.
Ba thay đổi kể trên, kết hợp với phần cứng chuyên biệt, con chip FPGA được các nhà khoa học tự tạo ra để tăng tốc xử lý số tam phân, đã cho phép các nhà nghiên cứu đạt được thứ mà họ nói là mô hình ngôn ngữ tạo ra hiệu năng so sánh được với những LLM mới nhất hiện tại, nhưng tiêu thụ điện năng và sức mạnh xử lý thì giảm đáng kể.
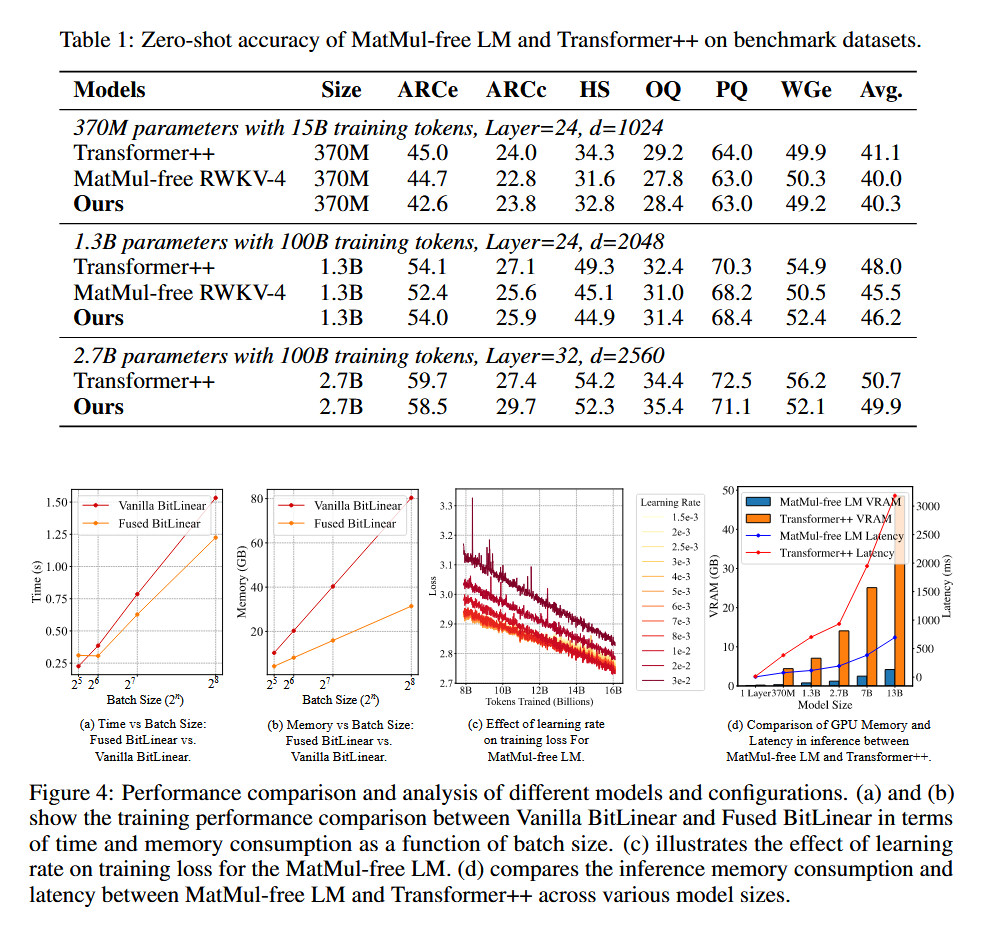
Trong nghiên cứu của các nhà khoa học Mỹ, họ vận hành LLM tính toán số tam phân thay vì nhân ma trận trên GPU phổ biến hiện nay, để đo đạc tiêu thụ điện năng và tốc độ xử lý. Nhưng kỹ thuật này hoàn toàn có thể được ứng dụng để phát triển những phần cứng tối ưu cho những phép tính đơn giản, chẳng hạn như chính con chip FPGA được phát triển trong quá trình nghiên cứu MatMul-free.
Nói cách khác, có khả năng công trình nghiên cứu này cũng sẽ giúp ích cho những phần cứng thiết bị tiêu dùng như laptop hay smartphone tăng tốc xử lý những tính năng AI tạo sinh.
Quảng cáo
Để đánh giá cách tiếp cận "bỏ nhân ma trận" của họ, các nhà nghiên cứu đã so sánh mô hình ngôn ngữ MatMul-free với một phiên bản dựa trên nền Llama-2 với ba kích thước, 370 triệu, 1.3 tỷ và 2.7 tỷ tham số. Tất cả những mô hình được thử nghiệm đều được huấn luyện thông qua cùng một bộ dữ liệu. Những mô hình kích thước tham số lớn thì được huấn luyện dựa trên 100 tỷ token dữ liệu văn bản.
Kết quả là các nhà nghiên cứu đưa ra khẳng định trong báo cáo, rằng mô hình ngôn ngữ MatMul-free giảm đáng kể bộ nhớ sử dụng. Cách tối ưu vận hành mô hình ngôn ngữ trên GPU của họ khiến quá trình vận hành giải phóng được tới 61% bộ nhớ trong quá trình huấn luyện, so sánh với trước khi tối ưu.

Ở khía cạnh công bằng hơn, so sánh với Llama 2 với 2.7 tỷ tham số vẫn còn đặt kỹ thuật loại bỏ nhân ma trận của các nhà khoa học Mỹ đứng sau rất xa so với những mô hình ngôn ngữ mới nhất trên thị trường hiện tại. GPT-4 vận hành ở ngưỡng trên 1 nghìn tỷ tham số. GPT-3 cũng vận hành ở ngưỡng 175 tỷ tham số từ tận năm 2020. Nhưng ở khía cạnh khác, cũng có rất nhiều các nhà nghiên cứu khác đang tìm ra những cách tối ưu LLM để chúng vận hành hiệu quả hơn ở ngưỡng tham số ít hơn, tức là tiết kiệm chi phí vận hành và chi phí phần cứng máy chủ.
Các nhà nghiên cứu cho biết, với hiệu năng và tiêu thụ điện năng như thế này, thì ở cùng tham số và cùng mức tiêu thụ điện năng, những mô hình vận hành dựa trên kỹ thuật không nhân ma trận có khi còn mạnh hơn và thông minh hơn những mô hình ngôn ngữ hiện tại, nếu vận hành chúng ở quy mô data center.
Dự báo của các nhà khoa học, là cách vận hành LLM họ mới sáng tạo ra, ở quy mô sức mạnh xử lý phần cứng ngưỡng 10^23 flops, tức là 100 nghìn exaflop, MatMul-free sẽ mạnh hơn LLM truyền thống hiện tại đang vận hành. Con số này tương đương với tổng hiệu năng điện toán cần thiết để huấn luyện những mô hình ngôn ngữ như Llama-3 8 tỷ tham số, hoặc Llama-2 70 tỷ tham số.
Tuy nhiên, các nhà nghiên cứu cũng thừa nhận giải pháp của họ cũng có giới hạn. Vì lý do giới hạn công nghệ, kỹ thuật xử lý mô hình ngôn ngữ không có nhân ma trận của họ chưa được thử nghiệm trên mô hình quy mô lớn, từ 100 tỷ tham số trở lên. Kết quả là, họ đang kêu gọi các tổ chức và các nhà nghiên cứu khác cùng các nhà đầu tư chung tay giúp sức để hoàn thiện kỹ thuật mới này.
Theo ArsTechnica
Khóa học Machine Learning cơ bản- Khoa học dữ liệu - AI 
==***==
Khoá học Quản trị Chiến lược Dành cho Lãnh đạo Doanh nghiệp
==***==
Nơi hội tụ Tinh Hoa Tri Thức - Khơi nguồn Sáng tạo

Để tham gia khóa học công nghệ truy cập link: http://thuvien.hocviendaotao.com
Mọi hỗ trợ về công nghệ email: dinhanhtuan68@gmail.com
---
Khóa học Hacker và Marketing từ A-Z trên ZALO!

Khóa học Hacker và Marketing từ A-Z trên Facebook!

Bảo mật và tấn công Website - Hacker mũ trắng
 KHÓA HỌC LẬP TRÌNH PYTHON TỪ CƠ BẢN ĐẾN CHUYÊN NGHIỆP
KHÓA HỌC LẬP TRÌNH PYTHON TỪ CƠ BẢN ĐẾN CHUYÊN NGHIỆP 

Khóa học Lập trình Visual Foxpro 9 - Dành cho nhà quản lý và kế toán 
Khóa học hướng dẫn về Moodle chuyên nghiệp và hay Xây dựng hệ thống đào tạo trực tuyến chuyên nghiệp tốt nhất hiện nay. 

Khóa học AutoIt dành cho dân IT và Marketing chuyên nghiệp 
Khoá học Word từ cơ bản tới nâng cao, học nhanh, hiểu sâu 
Khóa học hướng dẫn sử dụng Powerpoint từ đơn giản đến phức tạp HIỆU QUẢ  Khóa học Thiết kế, quản lý dữ liệu dự án chuyên nghiệp cho doanh nghiệp bằng Bizagi
Khóa học Thiết kế, quản lý dữ liệu dự án chuyên nghiệp cho doanh nghiệp bằng Bizagi 
 Khóa học Phân tích dữ liệu sử dụng Power Query trong Excel
Khóa học Phân tích dữ liệu sử dụng Power Query trong Excel 
Khóa học Lập trình WEB bằng PHP từ cơ bản đến nâng cao 
Khóa học Phân tích dữ liệu sử dụng SPSS - Chìa khóa thành công!

Khóa học "Thiết kế bài giảng điện tử", Video, hoạt hình kiếm tiền Youtube bằng phần mềm Camtasia Studio  Khóa học HƯỚNG DẪN THIẾT KẾ VIDEO CLIP CHO DÂN MARKETING CHUYÊN NGHIỆP
Khóa học HƯỚNG DẪN THIẾT KẾ VIDEO CLIP CHO DÂN MARKETING CHUYÊN NGHIỆP 
 HƯỚNG DẪN THIẾT KẾ QUẢNG CÁO VÀ ĐỒ HỌA CHUYÊN NGHIỆP VỚI CANVA Hãy tham gia khóa học để trở thành người chuyên nghiệp. Tuyệt HAY!😲👍
HƯỚNG DẪN THIẾT KẾ QUẢNG CÁO VÀ ĐỒ HỌA CHUYÊN NGHIỆP VỚI CANVA Hãy tham gia khóa học để trở thành người chuyên nghiệp. Tuyệt HAY!😲👍 

GOOGLE SPREADSHEETS phê không tưởng  Hãy tham gia khóa học để biết mọi thứ
Hãy tham gia khóa học để biết mọi thứ
Khóa học Ba, Mẹ và Bé - Cùng bé lập trình TUYỆT VỜI
Khóa học sử dụng Adobe Presenter-Tạo bài giảng điện tử 

Để thành thạo Wordpress bạn hãy tham gia khóa học  Khóa học sử dụng Edmodo để dạy và học hiện đại để thành công
Khóa học sử dụng Edmodo để dạy và học hiện đại để thành công  ==***== Bảo hiểm nhân thọ - Bảo vệ người trụ cột
==***== Bảo hiểm nhân thọ - Bảo vệ người trụ cột  Cập nhật công nghệ từ Youtube tại link: congnghe.hocviendaotao.com
Cập nhật công nghệ từ Youtube tại link: congnghe.hocviendaotao.com
Tham gia nhóm Facebook
Để tham gia khóa học công nghệ truy cập link: http://thuvien.hocviendaotao.com
Mọi hỗ trợ về công nghệ email: dinhanhtuan68@gmail.com

Bảo mật và tấn công Website - Hacker mũ trắng
KHÓA HỌC LẬP TRÌNH PYTHON TỪ CƠ BẢN ĐẾN CHUYÊN NGHIỆP

Khóa học AutoIt dành cho dân IT và Marketing chuyên nghiệp

Khoá học Word từ cơ bản tới nâng cao, học nhanh, hiểu sâu

Khóa học hướng dẫn sử dụng Powerpoint từ đơn giản đến phức tạp HIỆU QUẢ

Khóa học Thiết kế, quản lý dữ liệu dự án chuyên nghiệp cho doanh nghiệp bằng Bizagi
Khóa học Phân tích dữ liệu sử dụng Power Query trong Excel
Khóa học Lập trình WEB bằng PHP từ cơ bản đến nâng cao

Khóa học Phân tích dữ liệu sử dụng SPSS - Chìa khóa thành công!

kiếm tiền Youtube bằng phần mềm Camtasia Studio

Khóa học HƯỚNG DẪN THIẾT KẾ VIDEO CLIP CHO DÂN MARKETING CHUYÊN NGHIỆP

HƯỚNG DẪN THIẾT KẾ QUẢNG CÁO VÀ ĐỒ HỌA CHUYÊN NGHIỆP VỚI CANVA
Hãy tham gia khóa học để trở thành người chuyên nghiệp. Tuyệt HAY!😲👍

GOOGLE SPREADSHEETS phê không tưởng


Hãy tham gia khóa học để biết mọi thứ



Khóa học Ba, Mẹ và Bé - Cùng bé lập trình TUYỆT VỜI
Khóa học sử dụng Adobe Presenter-Tạo bài giảng điện tử

Để thành thạo Wordpress bạn hãy tham gia khóa học
Khóa học sử dụng Edmodo để dạy và học hiện đại để thành công
==***==
Bảo hiểm nhân thọ - Bảo vệ người trụ cột
Tham gia nhóm Facebook
Để tham gia khóa học công nghệ truy cập link: http://thuvien.hocviendaotao.com
Mọi hỗ trợ về công nghệ email: dinhanhtuan68@gmail.com
Nguồn: Tinh Tế
Topics: Công nghệ mới

